
Preliminarmente alla
raccolta dei dati sono stati definiti l’area di studio e l’intervallo temporale
di simulazione.
L’area di studio viene a
coincidere con l’attuale provincia di Milano ad esclusione del comune di San
Colombano al Lambro in quanto distaccato da quella che si può considerare
un’unica area urbanizzata. Si ricorda inoltre che dal 1993 circa 60 comuni sono
stati sottratti alla provincia di Milano e integrati nella nuova provincia di
Lodi. Riguardo alla città di Milano si
è preferito mantenere una suddivisione interna per avere una rappresentazione
quanto più veritiera possibile di una realtà piuttosto articolata e
disomogenea.
Per quanto riguarda l’arco
temporale, si è cercato di conciliare la carenza di dati con la necessità di
avere un numero sufficiente di anni per poter valutare la bontà della
simulazione. E’ stato possibile coprire un arco temporale di 19 anni, dal 1979
al 1998, ma si è dovuto ricorrere a
fonti differenti a discapito dell’omogeneità dei dati.
I dati demografici per i 186 comuni della provincia di Milano ( esclusi il capoluogo e San Colombano al Lambro) si basano sui rilevamenti dell’ISTAT riferiti alla fine di ciascuno dei 19 anni (Allegato A1 – Tabella 1). Al contrario, i dati demografici per la città di Milano provengono dalle registrazioni dell’anagrafe comunale secondo le 20 zone di decentramento stabilite dal Piano Regolatore Generale.
Sommando i valori di tutte le zone di
decentramento per ogni
anno e confrontando il totale
con i dati censuari dell’ISTAT,
emerge una lieve discrepanza che si può
ritenere di circa il 3% e quindi trascurabile (Allegato A1 – Tabella 2). Sempre riguardo ai dati del capoluogo si sono
aggregate alcune zone centrali in modo da avere aree confrontabili, per
dimensione, con le aree comunali esterne e secondo un criterio che
rispecchiasse l’espansione a macchia d’olio per corone circolari. Si sono così
definiti il centro storico, una prima corona esterna ed una seconda corona
periferica suddivisa al suo interno in 14 settori (Allegato A1 – Tabella 3).
Come criterio di
aggregazione si è adottata la somma semplice dei valori relativi alle zone di decentramento incluse in ogni nuova corona o
settore (Allegato A1 – Figura 1).
Essendo lo studio mirato a simulare la dipendenza dei prezzi
immobiliari dagli spostamenti demografici è risultato opportuno studiare non
tanto il valore assoluto della popolazione ma le variazioni percentuali da un
anno con l’altro (Allegato A1 – Tabella 4).
Le fonti consultate per
quanto riguarda il mercato immobiliare della provincia sono state due: CAAM e
CARIPLO.
I dati CAAM sono
disponibili solo a partire dal 1990 per quasi tutti i comuni della provincia,
sono registrati per semestre e differenziano il centro dalla periferia. I dati
CARIPLO sono al contrario disponibili dal 1979, registrati annualmente e
forniscono un valore unico per un numero di comuni elevato ma inferiore
rispetto alla CAAM. Purtroppo, per un certo numero di comuni non è quindi
disponibile alcun dato.
I dati CAAM forniscono una descrizione molto dettagliata ma troppo limitata nel tempo mentre quelli della CARIPLO danno una descrizione meno precisa ma che ricopre l’intero arco temporale. Si è quindi deciso di integrare una fonte con l’altra in modo da avere il massimo delle informazioni. Per minimizzare le differenze tra i dati dell’una e dell’altra fonte conviene considerare i prezzi CAAM per il centro del comune. Inoltre, poiché i dati anagrafici sono riferiti a fine anno, per i dati CAAM si sono considerati quelli del secondo semestre.
In conclusione (Allegato A2 – Tabella 1):
·
dal 1979 al 1989 si
hanno solo dati CARIPLO;
·
dal 1990 al 1998 si
hanno dati CARIPLO integrati con dati CAAM;
·
per alcuni comuni
non è disponibile alcun dato, per altri si hanno dati solo dal 1990 e per altri
ancora si hanno dati per tutto l’arco temporale.
Per la città di Milano, i dati CARIPLO sono invece molto dettagliati e quindi non si è ritenuto necessario integrarli con i dati CAAM: un’eventuale integrazione avrebbe comportato solo l’introduzione di disomogeneità e discrepanze (Allegato A2 – Tabella 2). Poiché i dati originali CARIPLO sono organizzati in quattro macrozone (A, B, C e D) e 53 zone interne, è stato necessario aggregare i valori immobiliari mantenendo la stessa suddivisione in corone e settori applicata ai valori demografici (Allegato A2 – Tabella 3).
Il
criterio di aggregazione è sempre la somma semplice (Allegato
A2 – Figura 1).
Dovendo studiare il mercato immobiliare per un ventennio durante il quale si è verificata una rilevante lievitazione dei prezzi, si è ritenuto opportuno considerare i valori immobiliari in termini reali, attualizzandoli. I tassi di inflazione sono stati reperiti presso l’ISTAT (Allegato A2 – Tabelle 4 e 5).
Come spiegato nel
capitolo precedente, il modello di automi cellulari AUGH2! richiede, tra gli
ingressi, uno scenario. La costruzione
di tale scenario implica preliminarmente la risoluzione di alcuni problemi.
Ad ogni cella dello scenario può essere associato uno ed un
solo stato, per di più qualitativo.
Al contrario, lo studio si basa su due insiemi di dati quantitativi: flussi di
popolazione e prezzi immobiliari. Si è allora pensato di aggirare il problema
raggruppando i dati numerici di ciascun insieme in tre classi qualitative :
flussi negativi, flussi positivi medi e flussi positivi rilevanti per le
variazioni demografiche; prezzi bassi, medi ed elevati per i valori del mercato
immobiliare (le modalità con cui è stata effettuata questa conversione sono
illustrate più avanti).
Ogni singolo stato sarà allora costituito da una
delle nove possibili combinazioni che si ottengono associando, a ciascuna
classe demografica, tutte le possibili classi di prezzi. La decisione di
riunire i valori in tre classi deriva dal tentativo di soddisfare
contemporaneamente due obiettivi: da un lato mantenere una distinzione tra
valori appartenenti a diversi ordini di grandezza, dall’altro minimizzare la
complessità di calcolo e quindi il set di stati
delle celle.
Inoltre, costruire lo scenario significa riuscire a conciliare
l’andamento tutt’altro che regolare dei confini amministrativi con una griglia
regolare di celle quadrate. D’altro canto, ai fini della simulazione, i confini
amministrativi non rivestono alcuna importanza, una volta che sia stato
costruito correttamente lo scenario. Si è quindi deciso di assumere come area
delle celle l’area media dei comuni e delle zone di Milano affinché ad ogni
comune potesse corrispondere teoricamente una singola
cella. Si è poi stabilito, come criterio di associazione, di assegnare ad ogni
cella lo stato del comune presente
nella cella in percentuale maggiore nel rispetto dei confini amministrativi.
In definitiva la
costruzione dello scenario richiede
che ad ogni comune e ad ogni zona di Milano venga associata una sola delle nove
possibili combinazioni variazioni
demografiche - prezzi immobiliari e che alle celle della griglia siano
associati gli stati secondo un
criterio di discretizzazione spaziale che rispecchi il più possibile la realtà.
Il programma IDRISI
offre la possibilità di creare mappe tematiche, di cross - correlarle e di
relazionarle ad una griglia. Sfruttando le potenzialità di questo sistema GIS è
stato possibile creare quindi una griglia per ogni anno, dal 1980 al 1998 .
Come base cartografica
di partenza si è usata la carta tecnica regionale, scala 1 :10000, disponibile
presso il Centro di Calcolo del Politecnico di Milano, in formato vettoriale.
Usufruendo del programma
ARCINFO si è estratta, dalla carta regionale,
la sola provincia di Milano.
Sempre in ambiente ARCINFO è stata creata la griglia (22 x 18) in
formato vettoriale ed il rispettivo database. Quest’ultimo è
inizialmente costituito da un solo attributo ossia dall’identificatore numerico
delle celle.
Poiché sulla carta tecnica regionale sono riportati solo i confini amministrativi comunali, per Milano è stato necessario aggiungere la suddivisione interna in centro storico, prima corona, settori della corona periferica. E’ stato possibile svolgere questa operazione tramite funzioni del programma ARC VIEW (Figura 3.1).
|
Figura 3.1 – Mappa vettoriale della provincia di Milano
Terminata questa prima
fase di elaborazione, sia la griglia sia la carta tecnica sono state importate
in IDRISI e convertite in formato raster. Questa conversione è stata necessaria
per poter usare la maggior parte dei comandi di IDRISI.
Prima di procedere
all’elaborazione delle mappe è stato indispensabile creare i database da
associarvi.
Si sono costruiti due
database tematici: in uno si sono raccolti i dati relativi alle variazioni
demografiche dal 1980 al 1998 e nell’altro si sono organizzati i dati
riguardanti il mercato immobiliare nel medesimo intervallo temporale.
In entrambi i database
le prime tre colonne hanno carattere identificativo: nella prima colonna sono
elencati gli indici rappresentativi dei comuni e delle zone di Milano, nella
seconda colonna sono riportati i nomi dei comuni e delle zone, nella terza sono
registrati i codici ISTAT dei comuni ed una
numerazione simbolica arbitraria delle sottozone di Milano. Riguardo agli
indici rappresentativi dei comuni, questi sono stati importati dal database
relativo alla carta tecnica regionale mentre per le sottozone di Milano sono
stati creati automaticamente dal programma ARC VIEW al momento della
digitalizzazione delle zone stesse.
Gli attributi dei due database sono stati inizialmente tabulati in Exel97 e poi importati in Access.2 dove, tramite apposita query, sono stati associati agli indici rappresentativi della carta tecnica. Nelle tabelle 3.1 e 3.2 si riportano, a titolo di esempio, le prime righe dei due database.
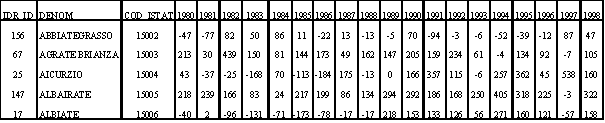
Tabella 3.1 – Estratto del database delle variazioni demografiche

Tabella 3.2 – Estratto del database dei prezzi immobiliari
Il database costruito come sopra specificato è stato
importato in IDRISI. Con un apposito comando si sono create, per ogni anno dal
1980 al 1998, due mappe tematiche. Il comando assign field infatti permette, tramite l’indice
rappresentativo, di associare ad ogni
elemento della mappa il corrispettivo valore di un attributo del database. Con
queste operazioni si sono ottenute dunque 36 mappe tematiche in cui ad ogni
singolo comune e a ciascuna delle 14 sottozone del comune di Milano risulta
associato un particolare valore demografico o un particolare prezzo.
Si è quindi proceduto
alla definizione delle soglie delle classi qualitative in cui raggruppare i
valori quantitativi.
Riguardo alle classi
demografiche, le elaborazioni necessarie sono state svolte solo sui comuni di
cui fossero noti i valori immobiliari. Si è preferito infatti non influenzare i
range con dei valori di cui poi non si sarebbe tenuto conto.
Dovendo definire la
prima soglia si è preferito distinguere tra variazioni positive e negative. La
prima classe risulta perciò compresa tra il valore negativo minimo -11,38 % ed
il valore 0.
Per definire le altre due
classi si è cercato quel valore in grado di ricadere tra il minimo storico ed
il massimo storico delle variazioni demografiche, per il maggior numero di
comuni. Una soglia così definita provoca la traslazione di classe per il
maggior numero possibile di comuni. Questo criterio viene giustificato dal
fatto che lo scopo dello studio non è
di descrivere una situazione statica ma un’evoluzione, un cambiamento nel
tempo.
Si sono quindi definite
la classe con variazioni demografiche
medie, compresa tra 0 e 4% e la classe con forti variazioni demografiche compresa tra 4% ed il valore massimo
37,71 %.
Grazie a queste scelte solo 4 comuni rimangono costantemente nella prima classe e altri 4 nella seconda; tutti gli altri comuni e le 14 sottozone variano almeno una volta la propria classe di appartenenza (Tabella 3.3 – Grafico 3.1).

Tabella 3.3 – Comuni della provincia e settori del capoluogo che non cambiano di classe demografica
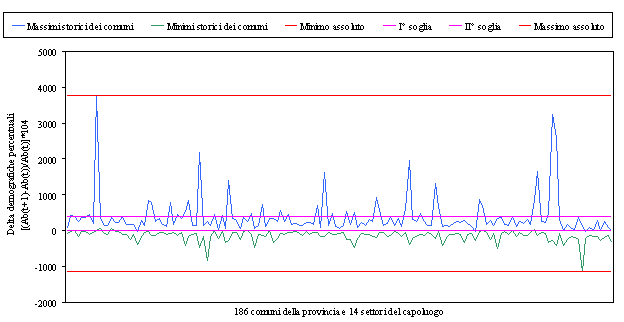 |
Grafico 3.1 – Range demografici
Anche le due soglie
delle classi economiche sono state ricercate in base al criterio di riuscire a
vedere il massimo numero di cambiamenti di classe. Nel caso particolare dei
comuni i cui prezzi sono disponibili solo dal 1990, il minimo storico è stato
valutato sul periodo 1990-1998.
In questo modo si sono ottenute: la classe prezzi bassi compresa tra il minimo 1380000 £/mq e la prima soglia 2400000£/mq; la seconda classe prezzi medi limitata superiormente dalla seconda soglia 3300000£/mq ed infine la terza categoria prezzi alti limitata superiormente dal valore massimo 12740000£/mq. Grazie a questa scelta, solo 7 comuni rimangono sempre nella prima fascia, mentre 5 comuni permangono nella seconda e solo due zone di Milano restano costantemente nella terza (Tabella 3.4 - Grafico 3.2 ).

Tabella 3.4 – Comuni della provincia e settori del capoluogo che non cambiano classe dei prezzi
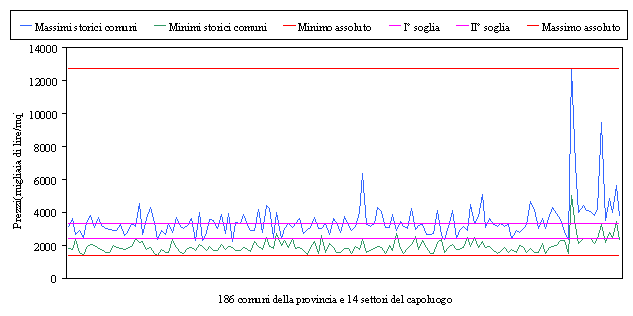 |
Grafico 3.2 – Range dei prezzi immobiliari
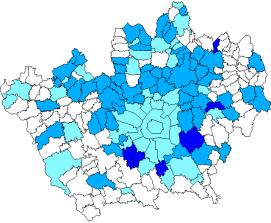
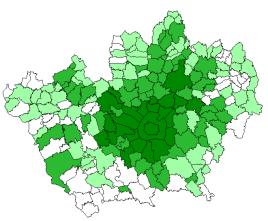
Avendo definiti i range, è stato possibile elaborare ogni singola mappa tematica sostituendo il dato qualitativo a quello quantitativo. Tramite il comando reclass tutti i comuni e le sottozone di una mappa tematica vengono raggruppati nelle tre classi sopra definite e nelle mappe finali ad ogni comune risulta associata, tramite il solito indice identificatore, solo la classe di appartenenza (Figure 3.2 e 3.3 - Allegato C1).
  |
Figura 3.2 – Classi demografiche – Anno 1990
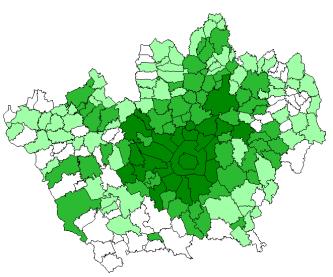  |
Figura 3.3 – Classi dei prezzi – Anno 1990
Prima di sovrapporre ad
ogni mappa tematica dei prezzi la corrispettiva mappa tematica demografica è
stato necessario eliminare da queste ultime i comuni di cui si ignorano i
valori immobiliari. Senza questo accorgimento la sovrapposizione
genererebbe tre combinazioni aggiuntive
portatrici di un’informazione incompleta. Come si potrebbe gestire una
combinazione forti variazioni
demografiche - prezzi incogniti ?
Partendo dalle due mappe tematiche dei prezzi del 1980 e del 1990, tramite il comando reclass si sono create due mappe binarie, una per l’arco 1980-1989 e l’altra per l’arco 1990-1998, tali che ai comuni privi di informazione sia assegnato il valore 0 caratteristico del background e a tutti i comuni restanti il valore 1. Sovrapponendo ad ogni mappa tematica demografica la mappa binaria tramite l’opzione [ first x second ] del comando overlay è possibile creare le mappe con le caratteristiche desiderate (Figura 3.4).
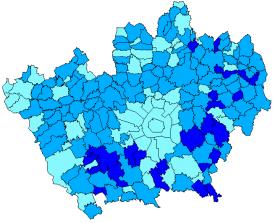 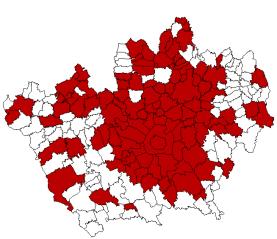
Classi demografiche – Anno 1980 Maschera 1980 – 1989
Classi demografiche dopo overlay |
Figura 3.4 – Operazione di overlay per filtrare i comuni con informazione completa
A
questo punto, per ogni
anno si è generata una mappa in cui i comuni portatori di informazione sono
raggruppati in nove classi:
• CLASSE 1 : variazioni demografiche negative - prezzi bassi
• CLASSE 2 : variazioni demografiche negative - prezzi medi
• CLASSE 3 : variazioni demografiche negative- prezzi alti
• CLASSE 4 : variazioni demografiche positive - prezzi bassi
• CLASSE 5 : variazioni demografiche positive- prezzi medi
• CLASSE 6 : variazioni demografiche positive- prezzi alti
• CLASSE 7 : variazioni demografiche positive elevate - prezzi
bassi
• CLASSE 8 : variazioni demografiche positive elevate - prezzi
medi
• CLASSE 9 : variazioni demografiche positive elevate - prezzi
alti
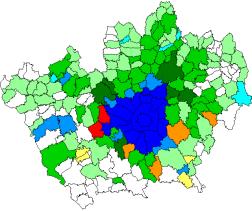
Questa operazione viene svolta automaticamente dal comando crosstab (Figura 3.5).
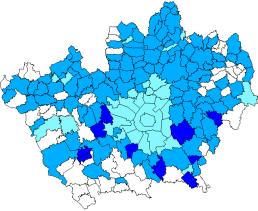 
Classi demografiche – Anno 1990
Classi dei prezzi – Anno 1990
Risultato del crosstab – Anno 1990
|
Figura 3.5 – Operazione di crosscorrelazione per la definizione degli stati finali
Per sovrapporre, alle 18 mappe così ottenute, la griglia ed associare ad ogni cella della griglia una delle nove classi sono state necessarie più elaborazioni. Come primo passo, tramite il comando reclass, da ogni mappa si sono estratte nove mappe monoclasse (Figura 3.6).
|
Anno 1998 Classe 1 – Anno 1998 Classe 2 – Anno 1998
Classe 3 – Anno 1998 Classe 4 – Anno 1998 Classe 5 – Anno 1998
Classe 6 – Anno 1998 Classe 7 – Anno 1998 Classe 8 – Anno 1998
Classe 9 – Anno 1998
|
Figura 3.6 -
Operazione di estrazione delle singole classi
Ogni mappa monoclasse
assegna il valore 1 ai comuni di una certa classe ed il valore di background a
tutti gli altri. A ciascuna mappa monoclasse è stata poi sovrapposta la griglia raster .
Come secondo passo, ad
ogni mappa monoclasse grigliata si è applicato il comando extract. Questa operazione ha prodotto una matrice di due colonne:
la prima colonna riporta
l’identificatore di cella, la seconda colonna riporta il numero di pixel
che in ogni cella assumono il valore 1.
Riunendo, anno per anno,
in una sola matrice le nove matrici estratte dalle nove mappe monoclasse dello
stesso anno è stato possibile osservare quanti pixel di ogni singola cella
appartengano alle differenti classi .
Si è a questo punto
costruita, in ogni matrice, una colonna aggiuntiva in cui si è riportato, cella
per cella, il numero della classe presente, nella cella stessa, con il maggior
numero di pixel o comunque con un numero di pixel superiore al 50% dei pixel
della cella.
Si riportano nella tabella 3.5, a titolo di esempio, alcune righe della matrice.
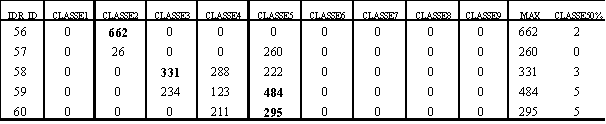
Tabella 3.5 – Ricerca della classe prevalente in
ogni cella in base al numero di pixel – Soglia 50% - Anno 1998
Come ultimo passo, per
ogni anno, è stato costruito un database
affiancando alla colonna con gli identificatori di cella le 18 colonne, una per ogni anno, con il
numero della classe da associare alle celle. Tramite il comando assign field si sono costruite 18
griglie, una per anno, in cui ad ogni cella è attribuita una sola delle nove
classi e dove alle celle di sfondo o prive di informazione è attribuito il
valore 0.
Si riportano nella tabella 3.6, a titolo di esempio, alcune righe del database.

Tabella 3.6 – Serie
storica delle classi prevalenti in ogni cella – Soglia 50%
Purtroppo i 18 scenari ottenuti presentano numerose celle vuote (valore 0) anche all’interno del dominio, in corrispondenza dei comuni di cui non è stato possibile trovare nessuna informazione riguardo ai prezzi immobiliari.
Si è deciso allora di
creare degli scenari più completi .
Per integrare gli
scenari si è deciso di sostituire la soglia del 50% con una soglia minima dello
0,1% : ad ogni cella si attribuisce il numero della classe presente, nella
cella stessa, con il maggior numero di pixel o con un numero di pixel superiore allo 0,1% dei pixel della cella.
Si riportano nelle
tabelle 3.7 e 3.8, a titolo di esempio, alcune righe della matrice e del
database.
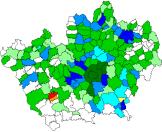
Laddove, all’interno del dominio, rimangano ancora delle celle vuote, a queste viene attribuito un valore che tenga conto dei valori delle celle circostanti per quello che riguarda i prezzi e che tenga conto dell’informazione demografica disponibile e quindi comunque recuperabile (Figura 3.7 - Allegato C2).

Tabella 3.7 – Ricerca della classe prevalente in ogni cella in base al numero di pixel – Soglia 0,1% – Anno 1998

Tabella 3.8 – Serie storica delle classi prevalenti in ogni cella – Soglia 0,1%
|
Anno 1998 – Soglia 50% Anno 1998 – Soglia 0,1%
|
Figura 3.7 – Riempimento ragionato dello scenario