Nel capitolo precedente
si è messa in evidenza la disomogeneità esistente all’interno del territorio
provinciale. Si sono delineate, fondamentalmente, cinque realtà distinte, dal
punto di vista demografico.
Osservando la
distribuzione spaziale delle zone e tenendo conto delle rispettive
caratteristiche si possono individuare tre realtà corrispondenti ai settori
predefiniti:
·
settore nord: è
un’area prossima alla saturazione. La
prima corona sta già attraversando una situazione di decrescita demografica
mentre le corone più esterne continuano ad assorbire un flusso demografico
positivo ma, nel corso del ventennio, si avvicinano all’inversione di tendenza;
·
settore ovest e
settore est: in queste zone si ha un continuo affluire di persone che fuggono da Milano. L’afflusso è
inversamente proporzionale alla distanza dal capoluogo: i comuni della
provincia hanno prezzi inferiori ma non offrono tutti i servizi disponibili nel
capoluogo da cui quindi ci si allontana
il meno possibile. La prima corona ha già assistito, prima degli anni ‘80,
all’arrivo di una prima ondata demografica e quindi, nel ventennio, vede
lentamente esaurirsi le proprie
potenzialità. La seconda fascia ha assistito ad un fenomeno identico ma in
ritardo (negli anni ‘80) ed attenuato. La fascia più esterna, essendo la più
distante dal capoluogo, ha risentito in misura marginale di quanto avvenuto
nelle fasce intermedie. Va notato che sono aree comunque con una certa densità già
all’inizio del ventennio studiato e hanno un’ economia fondata principalmente
sull’industria ed il commercio;
·
settore sud: è la
zona agricola della provincia ed è la più distaccata
da Milano. Risentendo, in misura minore rispetto agli altri settori, dell’influenza
del capoluogo, è l’unica area a non
aver ancora assistito, all’inizio degli anni’80, ad un forte afflusso
demografico. Proprio per questo è la sola zona che abbia preservato le proprie
potenzialità di espansione urbanistica
fino all’inizio del ventennio. Esaurendosi però le risorse edilizie
delle altre zone, il flusso uscente da Milano si è diretto verso quest’area che
è in continua espansione e che non ha ancora esaurite le proprie risorse.
L’obiettivo dello studio
è simulare gli spostamenti demografici dal capoluogo ai comuni della provincia
e la risposta del mercato immobiliare a questo esodo.
Da un lato si vuole
quindi studiare un fenomeno che leghi
Milano al resto della provincia, non al singolo comune ma all’intera area
provinciale. D’altro canto, la provincia di Milano appare come un sistema
chiuso costituito da un sottosistema omogeneo Milano e da un sottosistema disomogeneo provincia .
Quest’ultimo può essere diviso per densità, potenzialità urbanistiche,
economia, servizi, dipendenza dal capoluogo nelle tre zone sopra descritte
(nord, est - ovest, sud).
Entrare ulteriormente
nel dettaglio esula dallo scopo dello studio mentre considerare la provincia in
blocco comporta una generalizzazione eccessiva.
La divisione in settore
nord, settore sud , settore est - ovest è risultata essere la divisione alla
giusta scala: non coglie la singola realtà comunale ma permette di individuare
le diverse realtà provinciali.
Ai fini della simulazione interessa non tanto distinguere il nord dal sud e dalle regioni est - ovest quanto distinguere una zona in piena espansione urbanistica da una zona in continua crescita, anche se si tratta di un’espansione moderata, e da una zona satura, cui rimane poco da offrire. Nel caso particolare della provincia di Milano queste realtà sono facilmente correlabili a della zone geografiche ben precise coincidenti con, appunto, i quattro settori derivanti dall’analisi delle densità.
Allo scopo di
distinguere le zone geografiche della provincia cui corrispondono le diverse
realtà sopra descritte si è deciso di introdurre il concetto di identificatore di zona.
Un identificatore di
zona è un punto del territorio provinciale (una cella dello scenario) avente lo
scopo di segnalare il verificarsi di una certa realtà nel suo intorno.
Un identificatore di
zona è un indicatore di sviluppo demografico ossia di grado di saturazione
della zona ad esso circostante.
In conclusione avremo un
identificatore per ciascuna delle realtà sopra delineate:
·
un identificatore di zona in espansione per
individuare una realtà come quella che si ha nel settore sud;
·
un identificatore di zona in crescita moderata
per individuare una situazione come quella riscontrabile nelle zone ad est e ad
ovest;
·
un identificatore di zona prossima alla
saturazione per individuare una realtà come quella corrispondente al settore nord.
Milano viene invece
considerata un sottosistema omogeneo che svolge la proprio influenza
gravitazionale su tutta la provincia, radialmente, secondo corone circolari
concentriche.
Milano è un sistema con una propria dinamica: un
continuo calo demografico che solo negli ultimissimi anni si sta
attenuando facendo presagire un’inversione di tendenza e un mercato immobiliare
molto speculativo le cui variazioni si ripercuotono su tutto il territorio
provinciale.
Si tratta di un area con
densità molto elevate, superiori a quella di qualsiasi zona della provincia;
caratterizzata dall’assenza di risorse dal punto di vista del patrimonio
edilizio sia per la carenza di spazi sia per il fallimento o la mancata
realizzazione dei grandi progetti urbani e del recupero delle aree dismesse. Ma
è anche un centro di importanza internazionale nel campo del commercio, della
moda e della finanza.
E’ stato perciò
necessario introdurre un quarto identificatore denominato identificatore di Milano per indicare il comportamento di un’area
molto particolare quale quella del capoluogo.
Innanzitutto è opportuno
osservare che la provincia di Milano comprende aree differenti dal punto di
vista del raggiungimento della capacità insediativa portante e che da essa
dipendono le dinamiche demografiche e le conseguenti fluttuazioni immobiliari.
Al fine di analizzare ulteriormente le diverse realtà riscontrabili dal punto di vista della densità, per ognuna delle 11 sottozone (le stesse definite nel capitolo precedente) si è costruita la retta meglio interpolante i valori delle densità (Allegato B3).
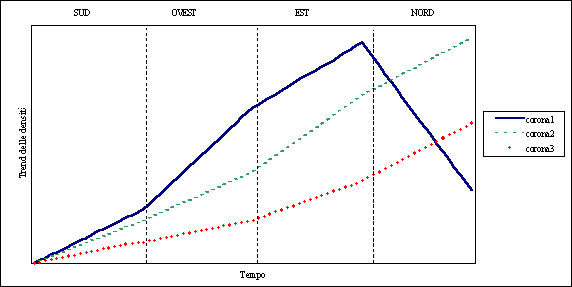
Una volta svolte le 11 regressioni lineari, si sono riunite, in un unico grafico (Grafico 5.1), tre curve così costruite:
·
Curva corona 1: si dispongono in serie, nel
seguente ordine sud à ovest à est à nord, le 4 rette ottenute dalla interpolazione
delle seguenti 4 curve di densità:
1.
Densità sud –
corona1
2.
Densità ovest –
corona1
3.
Densità est –
corona1
4.
Densità nord –
corona1
·
Curva corona 2: come sopra prendendo le rette
interpolanti le 4 curve di densità riferite alla corona 2 invece che alla
corona 1;
·
Curva corona 3: come sopra prendendo le rette
interpolanti le 4 curve di densità riferite alla corona 3 invece che alla
corona 1(per il settore sud, non essendoci comuni nella corona 3, si è
ipotizzato, per completare il grafico, un andamento uguale a quello assunto
dalla corona tre nel settore ovest).
Osservando da un punto
di vista solo ed esclusivamente qualitativo le 3 curve si può notare che:
·
per ogni corona, le
diverse realtà riscontrate nei settori possono essere viste come le fasi
consequenziali di uno stesso processo di iniziale crescita demografico –
urbanistica, fino al raggiungimento della capacità insediativa portante e di
successiva lenta decrescita;
·
le corone più
esterne sono in ritardo, nel processo evolutivo, rispetto a quelle più interne.
Allo scopo di definire possibili scenari futuri si sono ipotizzati i seguenti comportamenti:
1.
un’area con residue
potenzialità insediative continui ad attrarre à la curva mantiene il proprio trend crescente
(caso della corona3);
2.
un’area che nella
precedente fase di saturazione abbia raggiunto un valore massimo di densità
presenti una lenta inversione di tendenza à la curva inverte il proprio trend, da crescente
in decrescente (caso corona 2) ;
3.
un’area che abbia
già precedentemente saturato la propria capacità portante permanga nella fase
critica di calo demografico à la curva mantiene il proprio trend decrescente
(caso corona 1).
Nella fase previsionale, in definitiva, si ipotizza che:
·
Milano assista ad
un graduale rientro;
·
nel settore sud si
realizzi la medesima situazione prima riscontrata ad est e ad ovest;
·
nei settori est ed
ovest si verifichi quanto accaduto in precedenza nel settore nord;
·
nel settore nord si
presenti una realtà, non ancora riscontrata nella provincia, in cui il fenomeno
di svuotamento con conseguente calo demografico ed abbassamento dei prezzi si
estenda lentamente anche alle corone più esterne.
Per soddisfare quest’ultima ipotesi è stato necessario introdurre un ulteriore identificatore denominato identificatore di zona satura.
Il grafico 5.2 mostra
l’andamento qualitativo delle rette interpolanti in fase previsionale.
Le osservazioni e le
ipotesi precedenti hanno portato alla definizione di un progetto costituito da
3 automi in cascata:
1.
automa espansione
2.
automa transizione
3.
automa implosione
I tre automi collegati
in serie sono caratterizzati dallo stesso set di stati ma da regole differenti
e dalla concatenazione degli scenari di ingresso e di uscita.
Il primo automa espansione, è formato da regole costruite per simulare al meglio la fase di
espansione demografica nella provincia e la conseguente crescita dei prezzi
immobiliari, così come accade nei primi sedici anni della serie storica a
disposizione, (1980-1995). I settori nord, est - ovest e sud, si trasformano
secondo regole relative al proprio identificatore, con le seguenti
associazioni:
·
Identificatore di
zona in espansione => settore
sud;
·
Identificatore di
zona in crescita moderata => settore
est – ovest;
·
Identificatore di
zona prossima a saturazione => settore
nord.
L’area coperta dal
capoluogo ha regole proprie che simulano lo svuotamento di Milano, secondo
l’associazione:
·
Identificatore
di Milano => Milano.
Il secondo automa transizione, contiene solo regole
riferite al cambio degli identificatori, secondo le ipotesi previsionali sopra
descritte:
·
Identificatore di
zona in espansione =>
Identificatore di zona in crescita controllata;
·
Identificatore di
zona in crescita controllata => Identificatore di zona prossima a saturazione;
·
Identificatore di
zona prossima a saturazione => Identificatore di zona satura.
L’ identificatore di Milano non subisce cambiamenti.
Infine nel terzo automa implosione, sono utilizzate le regole
necessarie per permettere la costruzione di scenari futuri, secondo la seguente
associazione:
·
Identificatore di
zona in crescita controllata => settore sud;
·
Identificatore di
zona prossima a saturazione => settore est – ovest;
·
Identificatore di
zona satura => settore nord.
L’area di Milano ha
regole proprie che simulano il rientro nel capoluogo, come preannunciano gli
scenari storici riferiti agli ultimi tre anni della serie storica a disposizione
(1996-1998). L’associazione è quindi:
· Identificatore di Milano => Milano.
Grafico 5.1 – Concatenazione, per ogni corona, delle rette interpolanti le curve di densità dei 4 settori
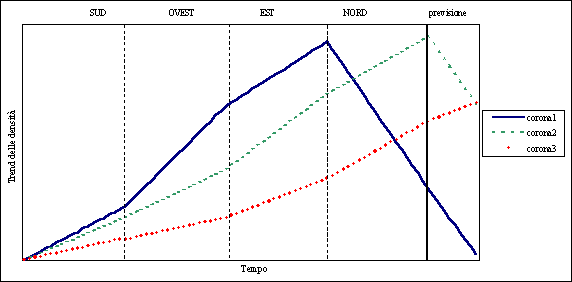
Grafico 5.2 – Prolungamento delle tre
curve riportate nel grafico 5.1 in base alle ipotesi previsionali
Prima di descrivere in
dettaglio le varie fasi di costruzione del modello è opportuno elencare
brevemente le ipotesi principali :
1.
sistema chiuso (non
sono previsti ingressi esogeni);
2.
non ci sono
interazioni ai bordi dello scenario (scenario a scomparsa);
3.
regole di
transizione variabili nello spazio (l’eterogeneità è garantita dall’influenza
dei diversi identificatori di zona);
4.
intorni uniformi
nella struttura (quadrata) ma non nella dimensione (raggio di influenza variabile
in funzione delle regole, max = 5 livelli);
5.
tempo discreto;
6.
automa a stati
finiti;
7.
sistema non
deterministico ( parametri di frequenza e probabilità);
8.
influenza delle
componenti esogene, quali reddito pro capite o agevolazioni fiscali trascurabili.
Il primo passo, nella
costruzione del modello, consiste nella definizione dell’insieme degli stati
della cella.
Si ricorda che, come
detto nel capitolo 2, ogni singolo stato è caratterizzato da un numero d’ordine
N, da un valore o caratteristica semantica V e da un colore C.
Per il modello in questione si è definito un insieme di stati (Tabella 5.1) contenente 17 elementi:
 |
Tabella 5.1 – Set di stati del
progetto
Il primo stato background viene assegnato a tutte le
celle prive di informazione. Una cella che si trova in questo stato nello
scenario iniziale rimane tale per tutta la simulazione, ad eccezione di quelle
adiacenti al contatore (si veda il diciassettesimo stato).
I nove stati, dal
secondo al decimo, corrispondono alle nove classi descritte nel paragrafo 3.2.3
(la numerazione degli stati risulta scalata di un’unità perché AUGH2! impone lo
stato 1 di default per il background). Ogni cella dello scenario il cui stato
iniziale appartenga a questo sottoinsieme, può, durante la simulazione,
permanere nello stato iniziale o assumere uno tra gli altri otto stati
possibili in base a delle precise regole la cui costruzione sarà descritta
successivamente.
I quattro stati
successivi corrispondono agli identificatori di zona la cui utilità è stata
spiegata all’inizio del capitolo.
Questi stati sono
assegnati ad un numero limitato di celle, il minimo necessario per distinguere
i quattro settori. Gli identificatori rimangono nel loro stato iniziale durante
le scansioni nell’automa espansione e
cambiano stato, assumendo uno degli altri tre valori possibili, nell’automa transizione.
Il quindicesimo stato corrisponde all’
identificatore introdotto appositamente per individuare il centro di Milano da
cui si propaga radialmente l’influenza gravitazionale che il capoluogo esercita
sul resto della provincia. La cella che assume tale stato assume lo stesso
comportamento di un cella background
ossia rimane sempre nel suo stato iniziale.
Il diciassettesimo stato
viene assegnato ad una sola cella dello scenario iniziale, posizionata lungo il
bordo. Ad ogni scansione dell’automa espansione
una cella priva di informazione passa dallo stato background allo stato contatore
così da poter tenere conto del numero di scansioni svolte. L’utilità di
questo stato è quindi quella di scandire il tempo. Nell’automa transizione tutte le celle
precedentemente trasformatesi, ritornano allo stato background cosi che passando all’automa implosione si riparta da zero per la nuova scansione.
Il sedicesimo stato
viene attribuito ad una sola cella dello scenario, più precisamente ad una
cella d’angolo, priva di informazione. Tale cella ha lo scopo di fare espandere
lo stato contatore lungo uno solo dei due lati dello scenario ossia svolge una
funzione di pura utilità.
Nell’automa espansione
è stato necessario considerare un intorno fino al quinto livello (il massimo
consentito da AUGH2!). L’evoluzione di ogni singola cella viene condizionata
dal fatto che essa appartenga ad un settore piuttosto che ad un altro ossia dal
fatto che nel suo intorno ricada un identificatore piuttosto che un altro.
Essendo lo scenario piuttosto esteso è
possibile assegnare ogni singola cella all’area di influenza del suo
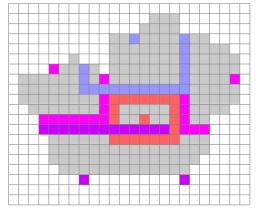
identificatore solo tramite un intorno di cinque livelli (Figura 5.1).
Nell’automa transizione gli identificatori cambiano il proprio stato indipendentemente dallo stato delle celle che li circondano. Si è quindi adottato un intorno ad un solo livello (Figura 5.2).
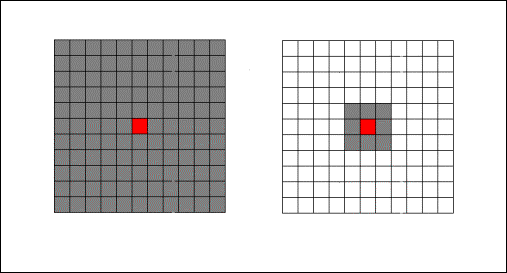
Figura 5.1 – Intorno
del progetto espansione e del progetto transizione
Lo scenario è una
griglia rettangolare, a celle quadrate, di dimensioni (24 righe x 22 colonne)
tali da contenere tutta la provincia di
Milano (escluso il comune distaccato di San Colombano al Lambro) (Figura 5.2).
Come scenario iniziale
per l’automa espansione si utilizza
la griglia costruita per il 1980, in base alla soglia dello 0,1 % .
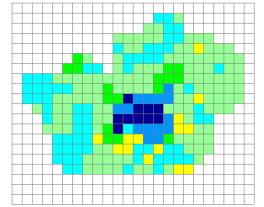
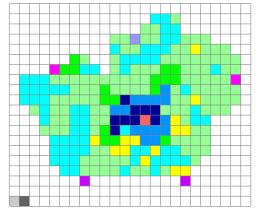
Una volta importato lo scenario generato con il software IDRISI è stato necessario aggiungervi il contatore e gli identificatori di zona (Figura 5.3).

Figura
5.2 – Sovrapposizione della griglia sulla carta dei confini amministrativi
della provincia
Lo start ed il contatore
sono stati posizionati nell’angolo in basso a sinistra così che il contatore evolva orizzontalmente, da sinistra
verso destra, lungo il bordo dello scenario. La provincia richiederebbe, per
essere totalmente coperta, una griglia di 18 righe; in realtà si è definito uno
scenario con un numero maggiore di righe affinché il contatore non invadesse celle adiacenti alle celle provinciali.
L’ identificatore di Milano, è stato posizionato al posto della cella corrispondente al centro storico di Milano. In un generico automa, la presenza di una cella stabile quale quella in questione potrebbe ostacolare il naturale evolversi dell’automa stesso, rappresentando un ostacolo alle trasformazioni delle celle ad essa adiacenti. Si è però ritenuto che nel nostro caso particolare il problema non sussistesse per il fatto che le trasformazioni non si propagano da un lato all’altro dello scenario attraversandolo ma si espandono a macchia d’olio partendo proprio dal centro di Milano.
La localizzazione degli
altri identificatori di zona ha richiesto più attenzione. Se fossero stati
posizionati all’interno del territorio provinciale avrebbero generato il
problema sopra descritto. Sarebbero stati dei semplici ostacoli e avrebbero
impedito alla celle ad essi adiacenti di evolvere come tutte le altre. Si è
quindi dovuto posizionarli ai bordi della periferia (non dello scenario!)
preferibilmente al posto di una cella di background.
E’ stato inoltre necessario posizionarli in modo tale che, con i rispettivi intorni, ricoprissero le loro aree di influenza, sovrapponendosi il meno possibile ma non lasciando scoperta alcuna zona. Cercando di soddisfare questi obiettivi si è trovata, come soluzione ottimale, quella mostrata in Figura 5.3.
|
Scenario iniziale importato da IDRISI Scenario iniziale del progetto
Aree di influenza degli indicatori di zona
|
Figura 5.3 – Preparazione degli scenari
La struttura delle regole segue la logica di tipo if then. Se la cella attiva è in un determinato stato e rispecchia le condizioni d’intorno specificate, allora la cella si trasforma nel nuovo stato, sempre nel rispetto di condizioni speciali, di frequenza o probabilità.
Gli obiettivi principali per la ricerca delle regole opportune sono:
· rispecchiare la relazione tra dinamica demografica e prezzi immobiliari, dedotta dalle analisi dei dati a disposizione;
· simulare l’evoluzione storica degli scenari, ottenuta dalle elaborazioni GIS.
Essendo difficile raggiungere gli obiettivi contemporaneamente, si è adottata una procedura che cercasse di ottimizzare entrambi, agendo in cascata. Inizialmente sono state scritte delle regole a buon senso, in base alle considerazioni emerse nella fase d’analisi del fenomeno. Questo gruppo di regole rappresenta tutti i passaggi di stato possibili, in ambiente deterministico e con intorni opportuni. La scelta dei passaggi di stato è mirata a garantire solo determinate trasformazioni delle celle che rispecchino le graduali variazioni dei valori delle variabili in gioco.
Risulta evidente dall’analisi del fenomeno che le fluttuazioni dei valori di popolazione e prezzi immobiliari sono molto lente e graduali, perciò sono state scelte regole che garantissero solo passaggi di stato unitari (da uno stato a quello ad esso adiacente). Ad esempio, se una cella è caratterizzata dallo stato 5 (crescita demografica - prezzi bassi) potrà solamente passare allo stato 2 (calo demografico – prezzi bassi), mantenendo la classe dei prezzi e passando alla classe di popolazione immediatamente inferiore, oppure allo stato 8 (forte crescita demografica – prezzi bassi) , mantenendo ancora la classe dei prezzi ma passando a quella demografica direttamente superiore, oppure allo stato 6 (crescita demografica – prezzi medi), mantenendo la classe di crescita moderata ma passando a quella dei prezzi immediatamente superiore.
Queste deduzioni sono avvalorate anche dai dati ricavati
dallo studio quantitativo della sequenza storica degli scenari, da cui emerge
con chiarezza che i passaggi di stato storicamente più frequenti sono quelli
più graduali. (Tabella 5.2).
Il valore di frequenza indica, in termini percentuali, quante volte avviene un determinato passaggio nel corso delle scansioni.
Ad esempio il passaggio 2 => 5 con frequenza pari al 100% significa che in tutti gli anni della serie storica esiste almeno una cella che si trasforma dalla stato 2 allo stato 5.
|
passaggi storicamente impossibili |
Passaggi storici in ordine decrescente di frequenza |
|||||||
|
2>4 |
2>5 |
100% |
4>7 |
44% |
3>7 |
22% |
4>9 |
6% |
|
2>7 |
3>3 |
100% |
6>7 |
44% |
3>9 |
22% |
4>10 |
6% |
|
2>9 |
4>4 |
100% |
7>4 |
44% |
5>9 |
22% |
9>8 |
6% |
|
2>10 |
5>5 |
100% |
2>3 |
39% |
7>3 |
22% |
5>10 |
6% |
|
3>8 |
6>6 |
94% |
3>2 |
39% |
9>9 |
22% |
4>2 |
6% |
|
7>8 |
5>2 |
83% |
3>5 |
39% |
10>9 |
22% |
4>5 |
6% |
|
7>10 |
5>8 |
78% |
4>6 |
39% |
5>7 |
17% |
7>2 |
6% |
|
8>4 |
6>3 |
78% |
6>9 |
39% |
8>9 |
17% |
7>9 |
6% |
|
8>7 |
8>5 |
78% |
6>2 |
33% |
10>6 |
17% |
9>4 |
6% |
|
8>10 |
8>8 |
78% |
6>4 |
33% |
3>10 |
11% |
9>5 |
6% |
|
9>2 |
5>1 |
72% |
6>8 |
33% |
5>4 |
11% |
10>3 |
6% |
|
9>10 |
3>6 |
67% |
7>6 |
33% |
6>10 |
11% |
10>7 |
6% |
|
10>2 |
2>2 |
61% |
7>7 |
33% |
7>5 |
11% |
|
|
|
10>4 |
5>6 |
61% |
8>2 |
33% |
8>3 |
11% |
|
|
|
10>5 |
4>3 |
50% |
9>6 |
33% |
9>3 |
11% |
|
|
|
10>8 |
2>6 |
44% |
8>6 |
28% |
9>7 |
11% |
|
|
|
10>9 |
3>4 |
44% |
2>8 |
22% |
4>8 |
6% |
|
|
Tabella 5.2 - Passaggi di stato della serie storica
Le elaborazioni dei dati hanno messo inoltre in evidenza come le variazioni dei prezzi seguano con un certo ritardo quelle della popolazione, e come le fluttuazioni del mercato immobiliare del capoluogo si propaghino a macchia d’olio con tempi proporzionali alla distanza dal centro.
Per cogliere le dipendenze temporali si è quindi associato ad ogni cella attiva un opportuno intorno che tenesse memoria delle variazioni locali degli stati ad essa adiacenti. Ad esempio una cella nello stato 5 (crescita demografica – prezzi bassi) può passare allo stato 6 (crescita demografica – prezzi medi) solamente se ha intorno a sé almeno tre celle nello stato 6, cioè se appartiene ad una zona in cui è già iniziato il processo di crescita.
Rispettando i criteri generali sopra descritti, si sono inizialmente costruiti 4 gruppi di regole deterministiche, a buon senso, in relazione alla dinamica di sviluppo di ogni singola zona:
1. set di regole relativo alla zona in espansione;
2. set di regole relativo alla zona in crescita moderata;
3. set di regole relativo alla zona prossima alla saturazione;
4. set di regole relativo a Milano.
I quattro gruppi costituiscono il database di regole del primo automa del progetto: l’automa cellulare espansione. Le regole sono state successivamente tarate confrontando i risultati delle simulazioni con i valori storici. Per spiegare in termini generici le caratteristiche di ogni gruppo, si riportano, a titolo d’esempio, delle regole tipo per ogni zona di sviluppo.
La tabella 5.3 contiene una regola relativa ad un’area prossima alla saturazione.
|
stato iniziale
stato finale
Fr. Pr. Applicabilità |
||||||
|
6 |
[6,6,6,Q,Q,Q,Q,Q] 7 100 100
sempre
|
|
|
|||
|
|
[6,6,6,6,6,6,6,6,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
|
|
|
|
|
[16,6,6,6,6,6,6,6,6,6,6,6,6,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
|
||
|
|
[6,6,6,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
||||
|
|
[13,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|||||
Tabella 5.3 - Descrizione di una regola tipo (zona in saturazione)
La tabella si legge nel modo seguente: “se la cella attiva si trova nello stato 6 (crescita demografica – prezzi medi) e nel suo intorno ci sono 3 celle dello stesso stato al primo livello, 8 nel secondo, 12 al terzo livello, 3 al quarto, l’identificatore di zona in saturazione (stato 13) all’ultimo livello e l’identificatore di Milano (stato 15) al terzo livello, allora la cella assumerà sempre lo stato 7 (crescita demografica – prezzi alti), con parametri di frequenza e probabilità d’attivazione pari a 100”.
L'esempio proposto evidenzia l’utilizzo degli intorni, al fine di creare ritardi nella propagazione dei prezzi immobiliari. In un’area tendente alla saturazione si suppone che, nella corona più vicina a Milano (lo stato 15 al terzo livello significa una distanza di circa 10 Km dal capoluogo), i valori immobiliari passino alla classe alta (stato 7) solo quando nelle corone più esterne i prezzi non sono più molto vantaggiosi (diffusione di celle allo stato 6).
In un’area in pieno sviluppo ci saranno invece regole a buon senso che riducono notevolmente il numero di celle in calo demografico (stati 2, 3, 4), mentre mantengono a lungo celle in forte crescita (stati 8, 9, 10). La tabella 5.4 mostra una regola appartenente ad una zona in espansione.
|
stato iniziale |
stato
finale Fr. Pr. Applicabilità |
|
|
||
|
8 |
[6,6,6,Q,Q,Q,Q,Q]
9 100
100 sempre |
|
|
||
|
|
[6,6,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
|
|
|
|
[6,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
|
|
|
|
[Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|||
|
|
[11,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
||||
Tabella 5.4 - Descrizione di una regola tipo (zona in espansione)
Il passaggio dallo stato 8 (forte crescita demografica – prezzi bassi) allo stato 9 (forte crescita demografica – prezzi medi), che significa innalzamento dei prezzi e mantenimento della forte crescita, è autorizzato in presenza di alcuni stati 6 (classe media di prezzi) nei primi tre livelli dell’intorno.
L’appartenenza alla zona in espansione è garantita dalla presenza dello stato 11 (identificatore di zona in espansione) all’ultimo livello.
A differenza della regola vista in precedenza, relativa ad un’area in via di saturazione, il passaggio di stato in questo caso richiede meno condizioni sull’intorno, coerentemente con la dinamica più rapida di un’area in pieno sviluppo.
La tabella 5.5 contiene una regola tipica di una zona in crescita moderata: l’appartenenza è segnalata dallo stato 12 (identificatore di zona in crescita moderata) al terzo livello.
Il passaggio dallo stato 5 (crescita moderata - prezzi bassi) allo stato 6 (crescita moderata - prezzi medi), è in funzione della diffusione dello stato 6 nei primi 3 livelli dell’intorno della cella.
|
stato iniziale
stato
finale Fr. Pr. Applicabilità |
|
|
5 |
[6,6,Q,Q ,Q,Q,Q,Q]
6 100 100 sempre
|
|
|
[6,6,6,6,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
[12,6,6,6,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
[Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
[Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
Tabella 5.5 - Descrizione di una regola tipo (zona in crescita moderata)
La tabella 5.6 contiene, infine, una regola d’esempio per l’area coperta da Milano.
L’appartenenza al capoluogo è identificata dallo stato 15.
|
stato iniziale
stato finale Fr. Pr. Applicabilità |
|||||
|
5 |
[Q,Q,Q,Q,Q,Q,Q,Q] 2 100 100
sempre
|
||||
|
|
[15,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
|
|
|
|
[Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|
|
|
|
|
[Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
|
|||
|
|
[Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q,Q] |
||||
Tabella 5.6 – Descrizione di una regola tipo (zona di Milano)
Nell’automa cellulare espansione, gli stati di crescita demografica interni a Milano (stato 5 nell’esempio), si trasformano, senza condizioni all’intorno, in stati di calo demografico (stato 2), seguendo la logica di simulare il costante svuotamento della città.
Oltre ai quattro set di regole sopra descritti, sono stati creati altri due gruppi, utilizzati solo nell’automa cellulare implosione senza pretese di validazione. Si tratta principalmente di regole a buon senso riferite ad una zona ormai satura (quella a nord) e all’area di Milano nella fase di rientro della popolazione.
Non possedendo informazioni sufficienti per tarare questo tipo di regole, che rispecchiano comportamenti appena accennati negli ultimi anni della serie storica, si è preferito considerarle come strumento esplorativo di possibili scenari di sviluppo, attribuendo una valenza previsionale alle sole regole già tarate nella fase di espansione.
Per una descrizione dettagliata di tutte le regole utilizzate si rimanda all’allegato C.